Normalization
One step in the risk detection process performed by nevisDetect is the calculation of the normalized risk score, also called normalization. To determine the overall risk of a specific HTTP request, nevisDetect may call different detection technologies. The result of each call to a detection service is a plug-in risk score. The goal of the normalization step is to create one single measurement for the risk of the HTTP request, by using the plug-in risk scores as input. For this, nevisDetect aggregates the plug-in risk scores into one normalized risk score, a single numerical value between 0.0 and 1.0:
- A normalized risk score of 0.0 signals no risk at all: the legitimate user has executed the request.
- A normalized risk score of 1.0 signals a maximum risk: It is for sure that the request has not been executed by the legitimate user.
The configuration of a normalized risk score is based on two elements:
- The configuration of the plug-in risk scores (which serve as input for the calculation of the normalized risk score), see chapter Training data.
- The computation algorithm used to calculate the normalized risk score, see chapter Normalization models.
The practical aspects of configuring the normalization are covered in the nevisDetect User Guide. In the following chapters, we focus more on the conceptual aspects of the normalization.
The general workflow for configuring the normalization is shown in the following picture:
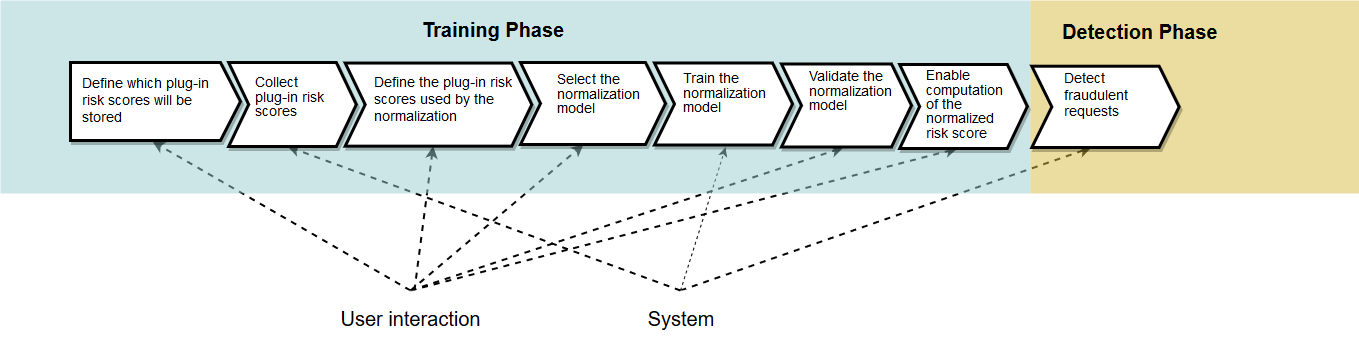
- As a first step, the user has to define which plug-in risk scores will be stored by the system.
- The system is now persisting plug-in risk scores.
- In a second step, the user defines the training data set, by selecting the required plug-in risk scores and a time frame.
- The user selects the normalization model in a third step.
- The system is now training the normalization model on a daily basis (or by user request).
- The user validates the normalization model after the trainings, and compares it with other normalization models.
- As a next step, the user must enable the calculation of the normalized risk core.
- Now fraudulent requests can be detected based on the normalized risk score computed by the normalization model. The user can stop the training of the model. If not, the normalization model will be trained daily.
The workflow described above consists of mutual actions of the user and the system. It is also possible to configure the normalization in a single step, during which no further user interaction is required. To achieve this, training of the model by the system, and computation of the normalized risk score during the processing of a HTTP request must be enabled. The flowcharts below show the interactions:
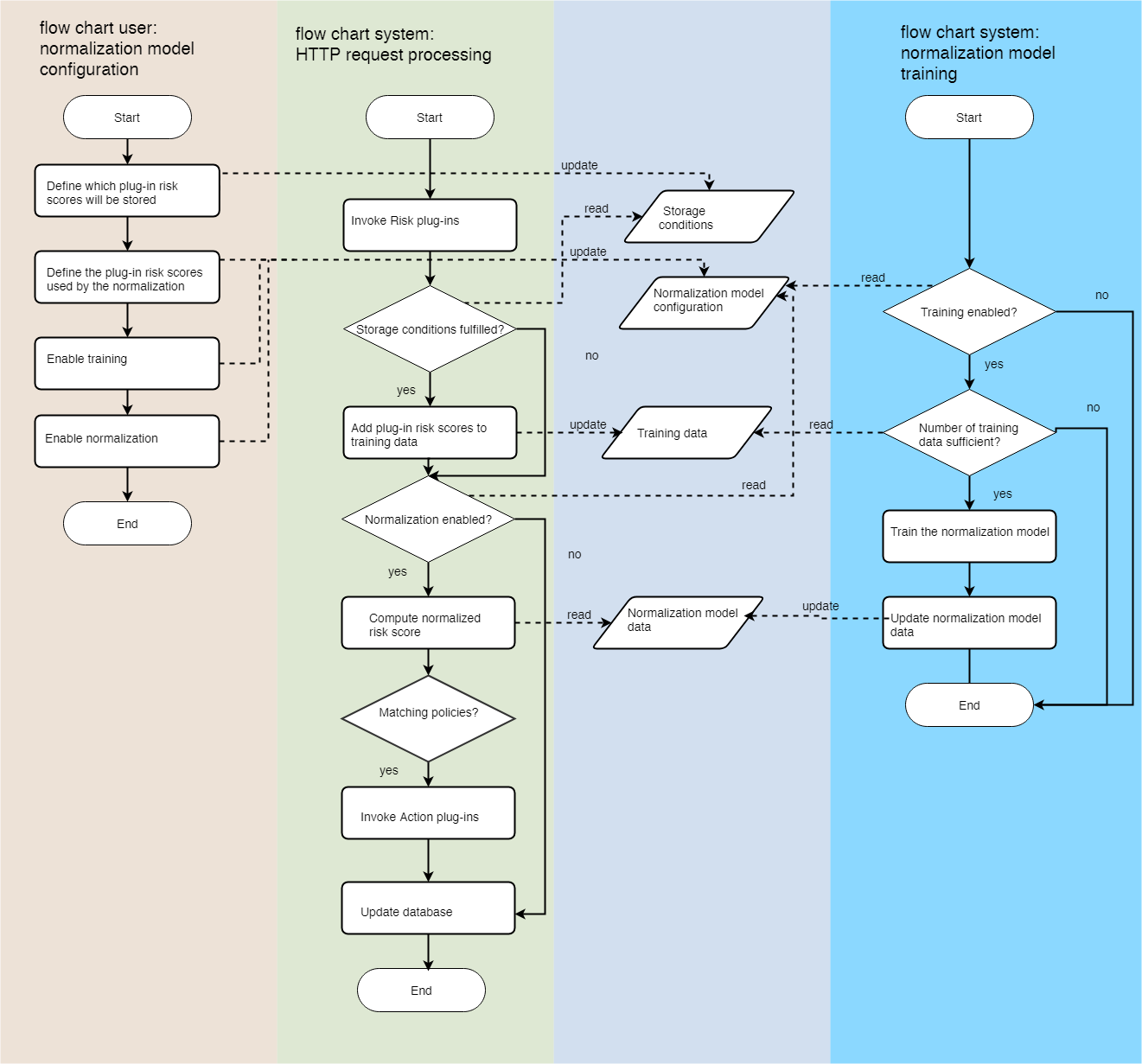
The user can define several normalization models at the same time. All computed normalized risk scores of the normalization models can be used in parallel for the detection of fraudulent requests.