Regression based models
Motivating example
To motivate the general idea of regression based models, let us look at the data points in the picture below. The question is which assignment of a normalized risk score to these data points makes sense:
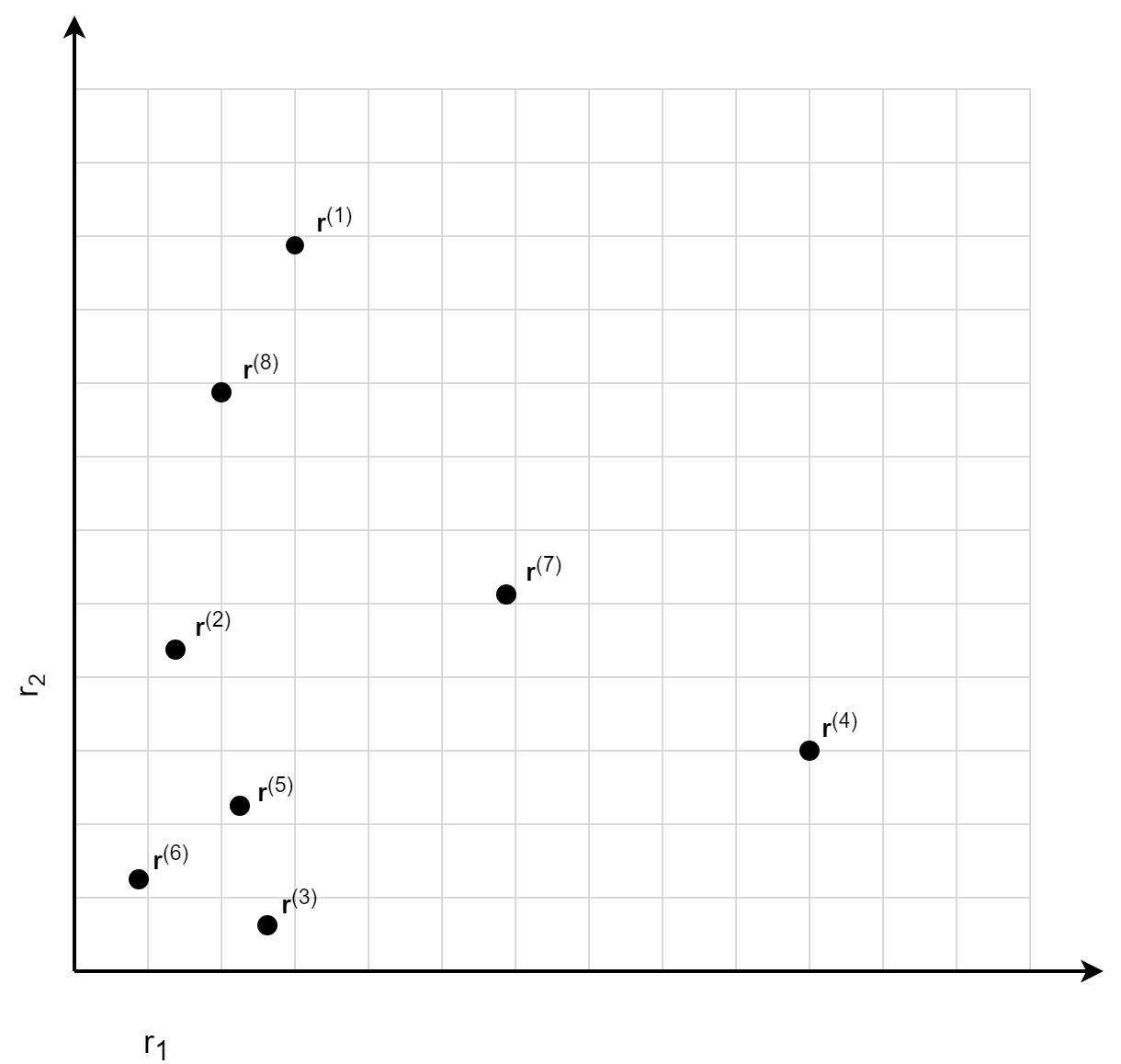
One possible answer would be:
- The data points r(1), r(7) and r(4) have the highest normalized risk score because they are the most extreme ones. No other data points are 'greater'.
- The data point r(8) has the second highest normalized risk score, since only the data point r(1) is 'greater'.
- The data points r(2), r(5) and r(3) are somehow similar, they all have the third highest normalized risk score.
- The data point r(3) has the lowest normalized risk score.
The answer above is based on counting the number of data points that are 'greater then' the data point under consideration. The used 'greater then' relationship says that the data point r'is 'greater then' r if all plug-in risk scores ri' of r' are greater then the plug-in risk scores ri of r. For generalizing the argumentation above we introduce the following notation:
- gt denotes the 'greater then' order relationship: r < gt r' <=> ri < ri' for all i = 1,2... ,D.
- D denotes the set of all observed data points: D = {r(1), ... ,r(N) } with N as number of observations.
- Dgt(i) denotes the set of all data points 'greater-then' the data point r(i) : Dgt(i) = { r ε D | r(i)
<gt r} - The size of a set S will be denoted by |S|
We then define: rnormalized( r(i)) = 1 - |Dgt(i)| / ( |D| -1 ) .
Applying the formula for the normalized risk score to the data points, we receive:
| r | Dgt | |Dgt| | rnormalized | | --- | --- | --- | --- | | r(1) | Dgt(1) = {} | 0 | 1 - 0/(8 -1) = 1 | | r(7) | Dgt(7) = {} | 0 | 1 - 0/(8 -1) = 1 | | r(4) | Dgt(4) = {} | 0 | 1 - 0/(8 -1) = 1 | | r(8) | Dgt(8) = {r(1)} | 1 | 1 - 1/(8 -1) = 0.86 | | r(2) | Dgt(2)= { r(1) ,r(8) , r(7)} | 3 | 1 - 3/(8 -1) = 0.57 | | r(5) | Dgt(5)= { r(1) ,r(7) , r(4)} | 3 | 1 - 3/(8 -1) = 0.57 | | r(3) | Dgt(3) = {r(1) ,r(7) , r(4)} | 3 | 1 - 3/(8 -1) = 0.57 | | r(6) | Dgt(6) = {r(1),r(8) , r(7),r(4),r(2),r(5)} | 6 | 1 - 6/(8 -1) = 0.14 |
Artificial response variable
The normalization problem itself is an unsupervised problem, since we do not have any response variable. We now use the counting approach described above to generate an artificial response variable y for every observed data point r(i): y(i) = 1 - |Dgt(i)| / ( |D| -1 ) . By introducing the artificial response variable y(i) , we have turned the unsupervised problem into a supervised regression problem:
- We have a training data set { (r(1),y(1) ), (r(2),y(2) ).. , (r(N),y(N) )} and want to learn a function N, y = N(r).
- The normalized risk score is the prediction of that function: rnormalized = N(r).
The big advantage is that there are many well-established techniques for solving a regression problem. Another important aspect is that the training data set { (r(1),y(1) ), (r(2),y(2) ).. , (r(N),y(N) )} is fulfilling the Proximityproperty. And so we expect that the prediction function N also tries to fulfill that property. In the following we describe two different normalization models that are based on solving the regression problem formulated above.
Ordinary least square normalization model
In the ordinary least square normalization model (OLS-model), we use a linear regression function N: rnormalized = N(r) = wT· r + a with a D-dimensional weight vector w and scalar intercept a. Further we use a use a squared loss function. The model parameters w and awill be computed by the gradient descent method.
The following pictures are showing 657 data points of BehavioSecSession and BehavioSecTransaction plug-in risk scores (denoted by r1 and r2) from a nevisDetect test system and a level plot of the trained normalization:
Note that the data are not realistic, since the test system has frequently being used for demonstration purposes with a confidence threshold of 0.0.
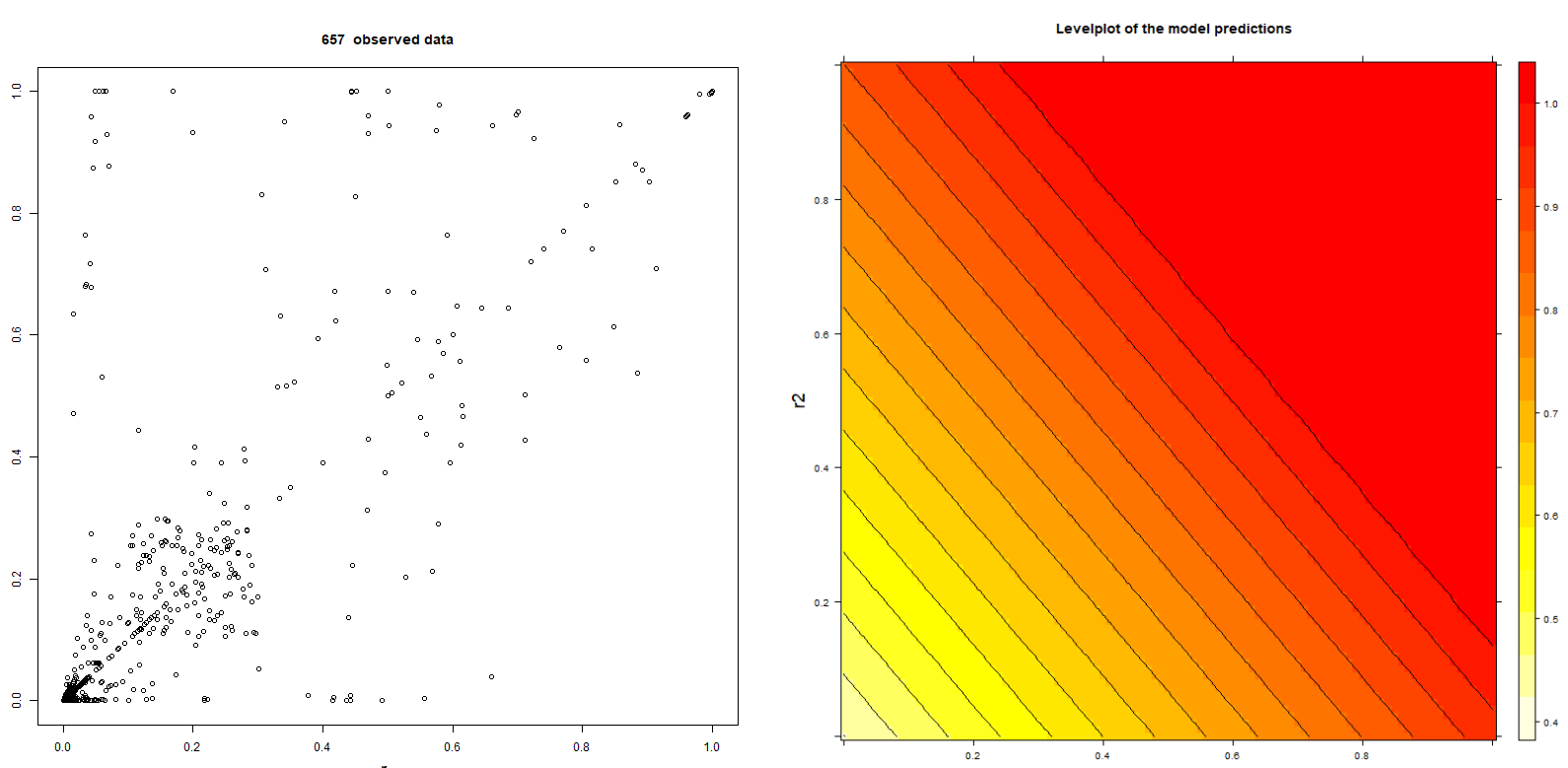
The advantages of the ordinary least square normalization mode are:
- Training the model is fast, stable, and also suited for a large training data set.
- The model parameters
wand acan be interpreted by a human being. - The Monotonicity property is fulfilled.
The disadvantages are:
- Using a linear regression function is an over-simplification.
- The
Proximityproperty is in general not fulfilled.
Support vector regression normalization model
The normalization model described here is experimental.
A more advanced approach for solving the regression problem is the Support Vector Machine Regression (SV Regression). With this approach, also non-linear dependencies between the plug-in risk scores and the normalized risk score can be trained. The support vector regression normalization model (SVR-model) uses an approach with a radial kernel. The SV Regression has two hyper-parameters:
- The box constraint parameter C.
- The hyper-parameter γ in the radial kernel exp( -γ || r(i) - r(j) ||2 ).
The hyper-parameter γ is controlling the contribution of the support vectors to the predicted normalized risk score. In case of a large γ, the term exp( -γ || r(i) -r ||2 ) is only contributing if the support vector r(i) is near to r. In case of a smallγ, the term is also contributing if r(i) is far away from r. Thus, it is possible to control the conflicting Monotonicity and Proximity properties by choosing appropriate values of γ and C. A large value of γ favors the Proximity property. The pictures below show the level plots of two trained normalization models, the first with γ = 0.1 and the second with γ = 0.01. For both models C = 10 and the 657 data points shown above have been used for training.
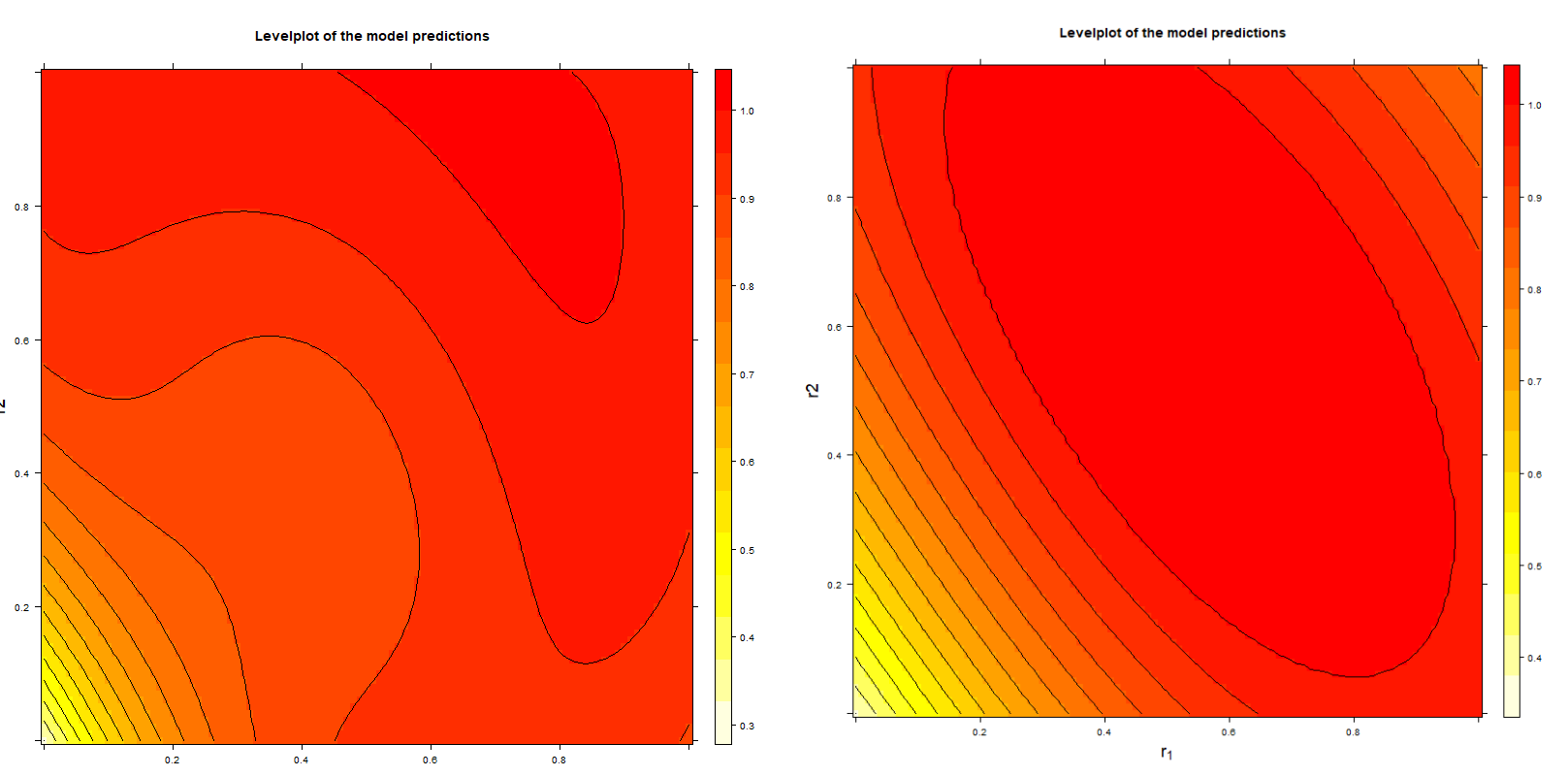
It would be desired to have a single hyper-parameter in the range [0,1] and the hyper-parameters are being computed by the system γ and C. In the current version that is not possible; the hyper-parameters γ and C haven been chosen by hand.