Normalized risk score calculation
Besides the creation and adaptation of policies, the security expert decides how to calculate the normalized risk score out of the plug-in risk scores. The normalized risk score of an HTTP request is one single measurement for the request's risk, based on the various risk scores coming from the different detection technologies or plug-ins. There are various algorithms available to calculate the normalized risk score.
The task of the security expert is to configure and test normalization models that can be used to calculate normalized risk scores. This task involves the following use cases:
- Specifying how to handle plug-in risk scores
- Creating training data sets
- Configuring and training normalization models
- Testing a normalization model
- Viewing the statistic details of a model
Use case: Specifying how to handle plug-in risk scores
The normalized risk score of an HTTP request ist based on the various risk scores coming from the different detection plug-ins. So specifying how to handle these plug-in risk scores is the first step in the process of configuring a normalization model.
The handling of risk scores includes the definition of the storage conditions. First specify what to do when an HTTP request does not deliver all plug-in risk scores. You also have to decide how to handle risk scores with a low confidence level. The confidence level of a risk score shows how confident nevisDetect is about the correctness of a risk score value.
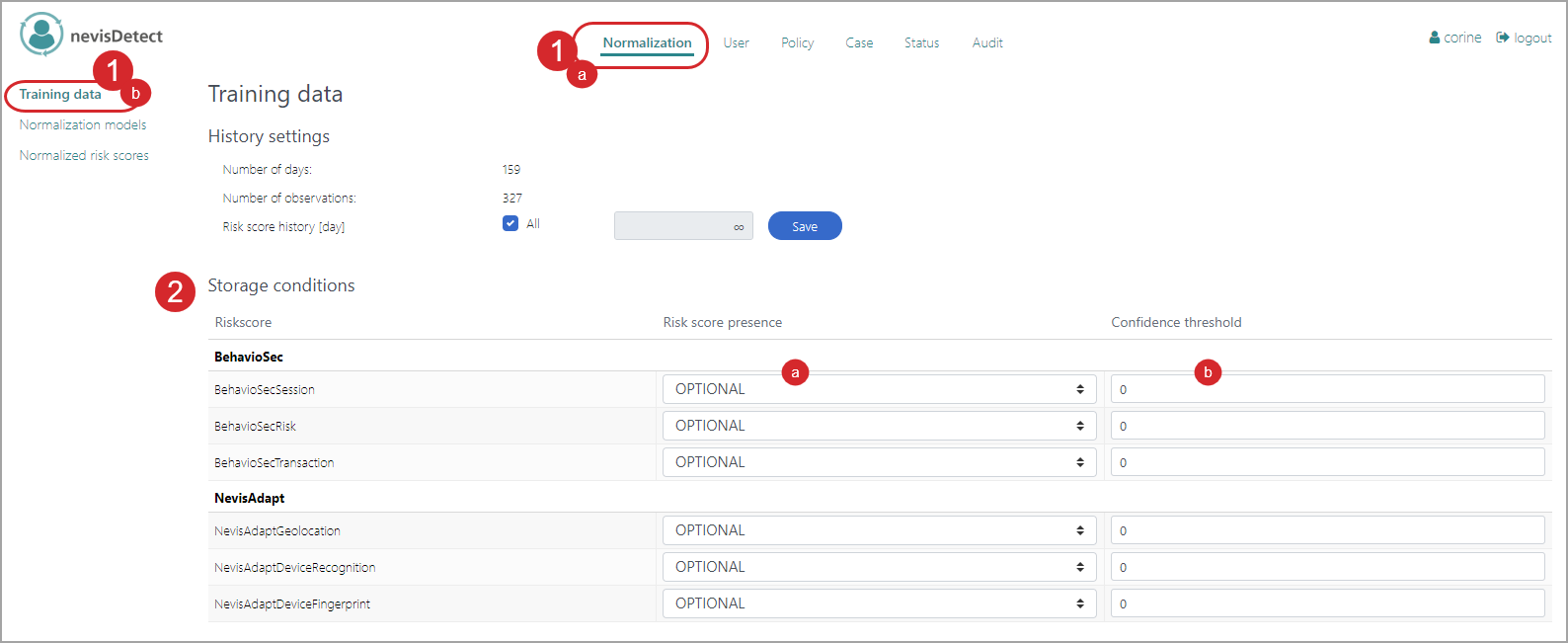
You define these settings in the Training data view of the Normalization section. This is how you have to proceed (see the figure below - the numbers in the figure correspond with the numbered steps below):
- To open the Training data view in the nevisDetect web application,
- Select Normalization from the top menu.
- Then select Training datain the navigation on the left.
- You define the storage condition per plug-in risk score in the Storage conditions field. A storage condition consists of a qualifierregarding the presence of the plug-in risk score, and a numeric confidence threshold.
- You set the qualifier for the presence of the risk score in the Risk score presence field.
Some detection technologies cannot deliver a risk score for every HTTP request. For your training purposes, such HTTP requests might be useless, as they do not deliver the complete set of risk scores. The Risk score presence field defines how to deal with such requests, per risk score. The following values for the qualifier are defined:
- IGNORE means that the respective plug-in risk score will never be stored.
- REQUIRED means that the presence of this plug-in risk score is required. If the plug-in risk score is not present for the HTTP request, no plug-in risk scores at all will be stored for the corresponding HTTP request.
- OPTIONAL means that the plug-in risk score is optional. It will be stored if present. This setting has no influence on the storare of the HTTP request's other plug-in risk scores.
- Set the qualifier for the presence of the risk score per plug-in risk score. If it is not clear which plug-in risk scores you need, configure the qualifier OPTIONAL.
- You define the confidence threshold in the Confidence threshold field, by entering a numeric value between 0 an 1. If the confidence of the plug-in risk score is below the threshold, the risk score will not be stored.
- You set the qualifier for the presence of the risk score in the Risk score presence field.
Some detection technologies cannot deliver a risk score for every HTTP request. For your training purposes, such HTTP requests might be useless, as they do not deliver the complete set of risk scores. The Risk score presence field defines how to deal with such requests, per risk score. The following values for the qualifier are defined:
For more information on the Training data view, see Normalization section.
Use case: Creating training data sets
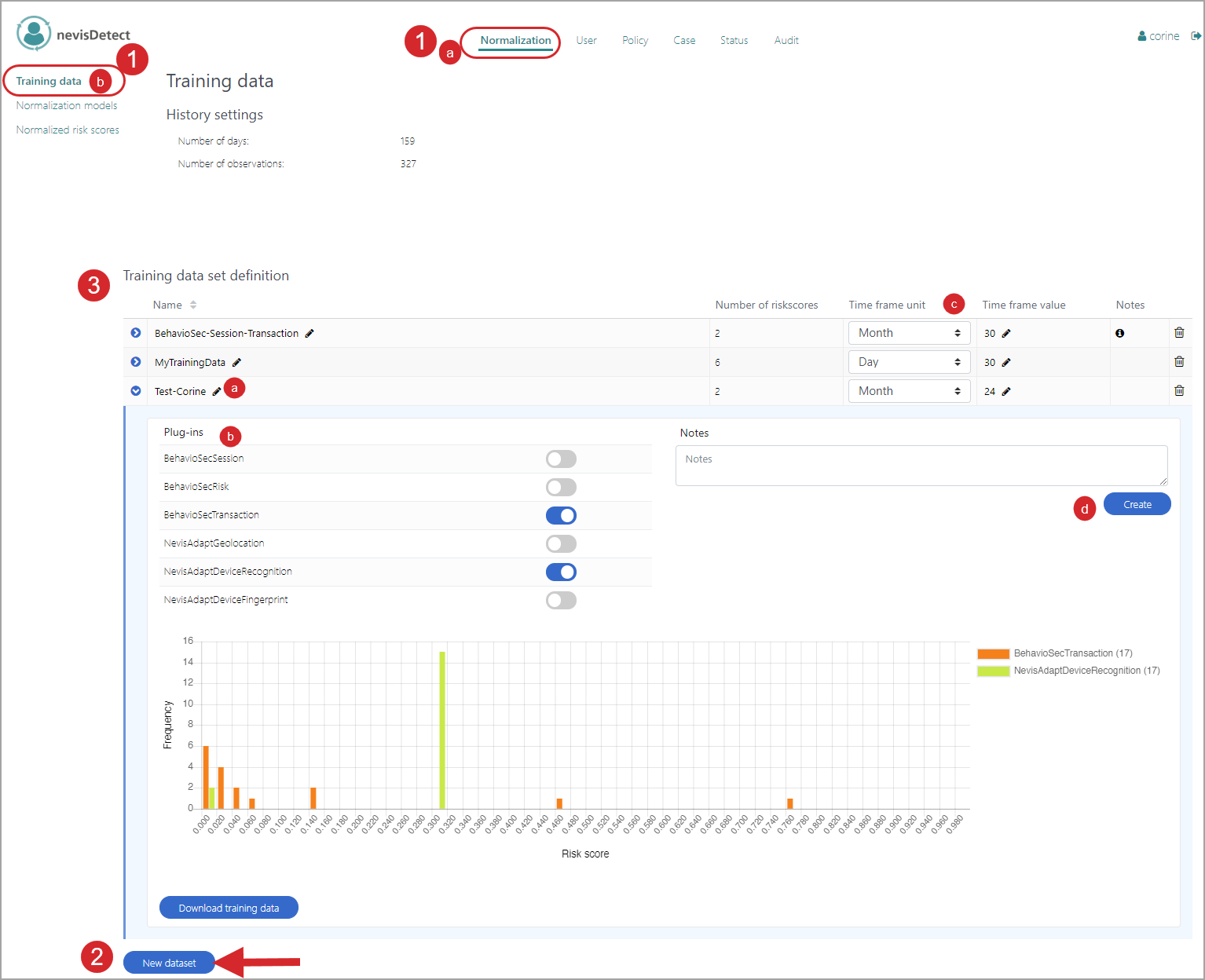
Defining training data sets is the second step in the process of configuring a normalization model. You use these data sets later on for training and testing your normalization models (and as such for calculating the normalized risk score). Training data sets are defined in the Training data view of the Normalization section. This is how you have to proceed (see the figure below - the numbers in the figure correspond with the numbered steps below):
- To open the Training data view in the nevisDetect web application,
- Select Normalization from the top menu.
- Then select Training datain the navigation on the left.
- Click New dataset.
- You configure the training data sets in the Training data set definition field. Per training data set,
- Click on the Pencil icon to specify a suitable name for the data set. The normalization models refer to training data sets by their names. Therefore, be sure that the name is unique.
- Select the plug-in risk scores to include in the training data set, under Plug-ins.
- Set the time frame to consider, in units ("Day" or "Month"). Additionally, you specify the number of units to consider (fieldTime frame value). For example, if you select the time frame unit "Month" and set the time frame value "12", then all relevant risk scores from the past year (12 months) are included in the training set.
- Click Create to create the new training data set.
The number of the selected plug-in risk scores defines the dimension of the training data set, whereas the time frame defines the size. Due to computational reasons, the total amount of training data must be limited. However, you can configure several training data sets without influencing the storage space. For more information on the Training data view, see Normalization section.
Use case: Configuring and training normalization models
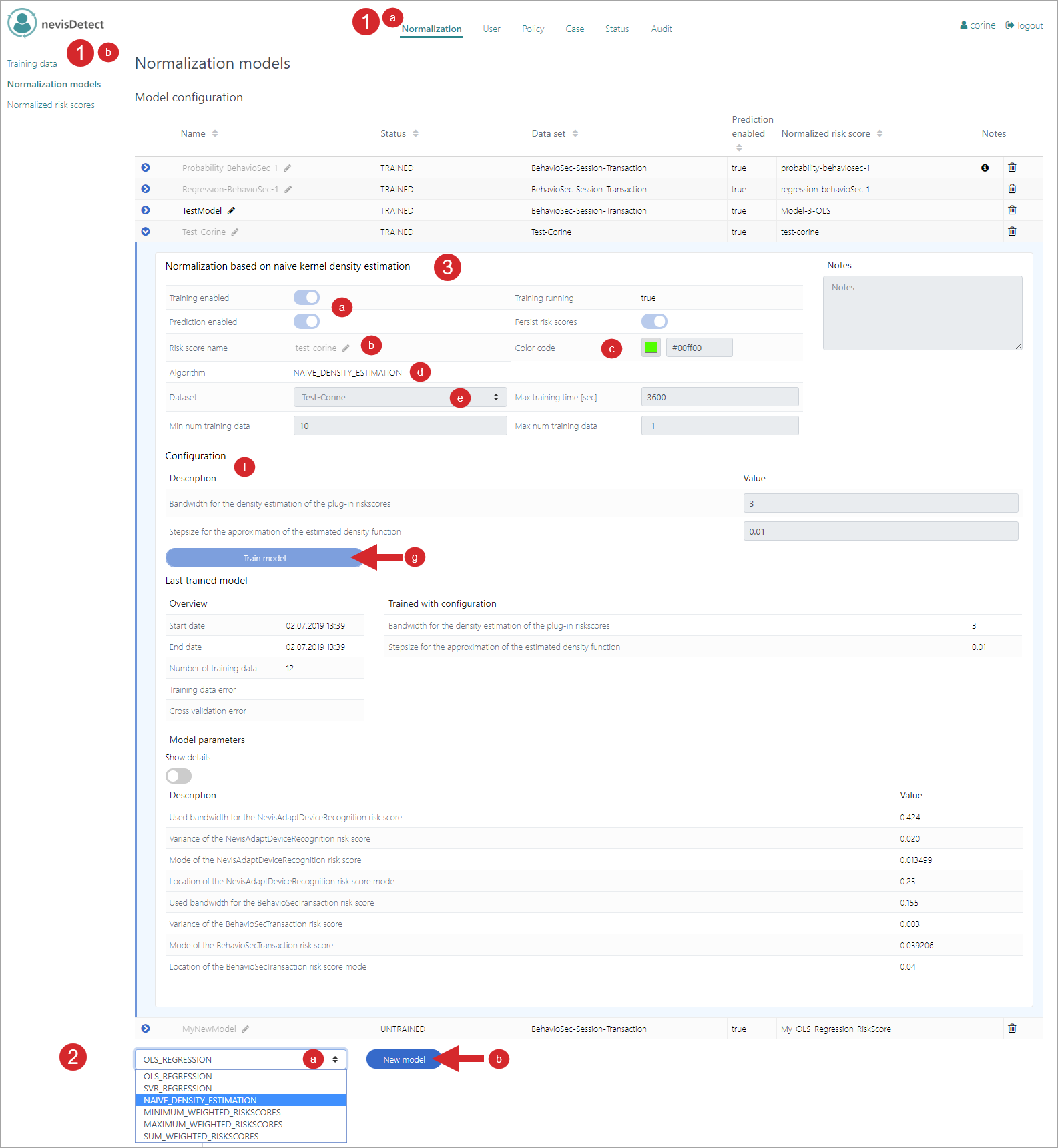
In the previous use cases, it was explained how to handle the plug-in risk scores and how to create a training data set. The next step is to configure and train a normalization model. You do this in the Normalization models view of the Normalization section. Proceed as follows (see the figure below - the numbers in the figure correspond with the numbered steps below):
To open the Normalization models view in the nevisDetect web application,
- Select Normalizationfrom the top menu.
- Then select Normalization models in the navigation on the left.
A normalization model is based on a normalization algorithm. Select this algorithm before you can create a new model. You do this in the drop-down menu next to the New model button (see no. 2 in the next figure). The following algorithms are available: OLS regression model, SVR regression model, Naive density estimation, Minumum weighted risk scores, Maximum weighted risk scores, Sum weighted risk scoreFor a description of all available normalization models, see Normalization models in the nevisDetect reference guide.
- Select a normalization algorithm from the drop-down menu.
- Click New model to create a new normalization model based on the algorithm you just selected.
Now you can configure your new normalization model. You do this in the field that opens when you have clicked New model. Perform the following steps:
- First specify some general settings, such as whether to enable training or prediction. For this, click the buttons Training enabled or Prediction enabled, respectively. Additionally, define whether to store the risk scores, by clicking the button Persist risk scores.
- In the field Risk score name, specify a name for the normalized risk score calculated by this normalization model. This name is used in all graphical overviews.
- In the Color code field, choose a color for the normalized risk score. The risk score is shown in this color in graphical overviews.
- The Algorithm field displays the normalization algorithm on which this normalization model is based.
- Select the data set that you want to use for training your model in the field Dataset. The data sets you can choose here are the ones you defined in the Training data view, see Use case: Creating training data sets. You can also set the minimum and maximum required number of HTTP requests for the training of your model, as well as the maximum training time in seconds (the fields Min num training data, Max num training data and Max training time (sec), respectively).
- The Configuration field allows you to specify settings that are specific for this respective normalization model.
- Click the Train model button to train your model. The training details appear below the button as soon as the training is finished.
For more information on the Normalization models view, see Normalization section.
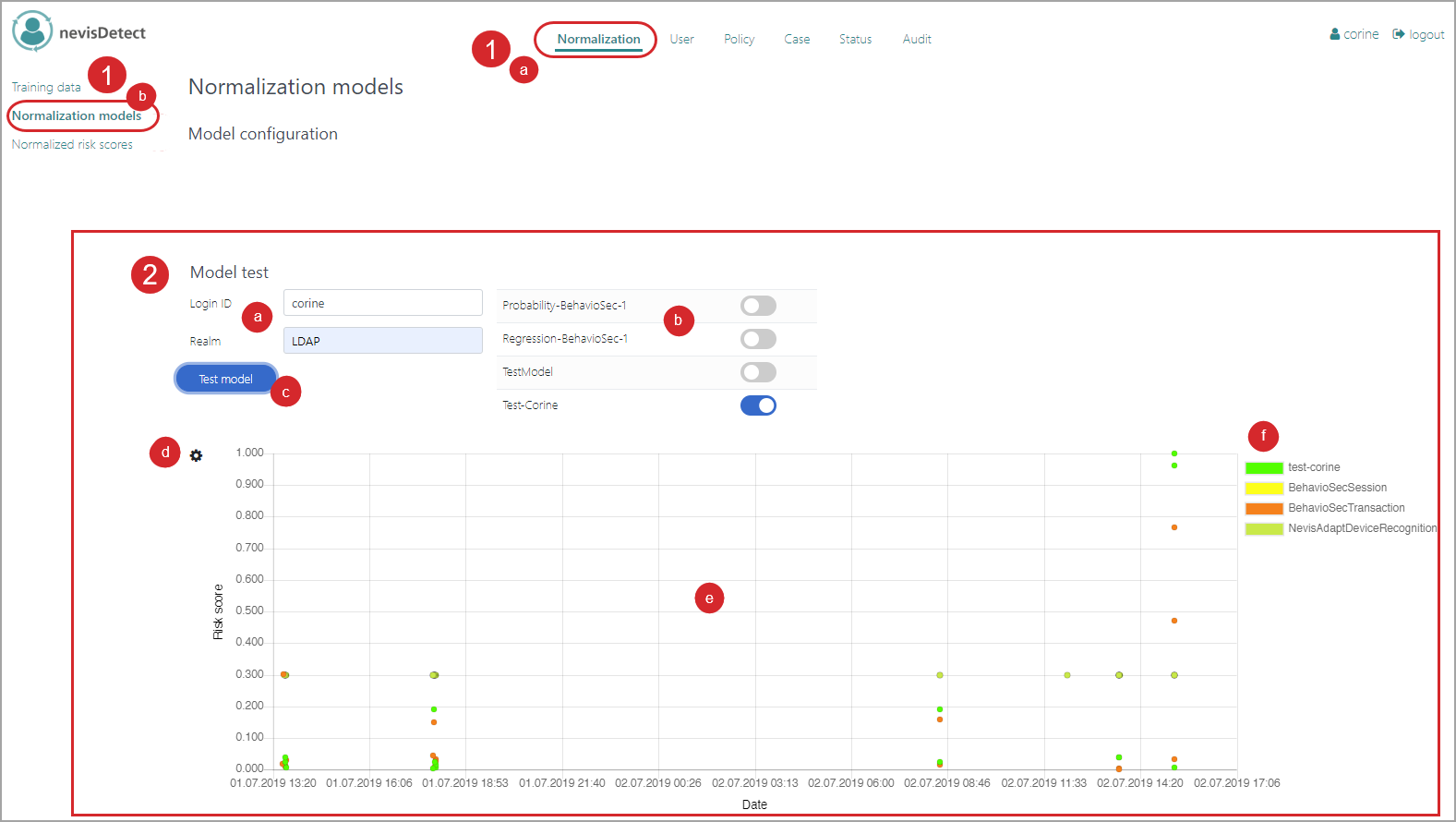
Use case: Testing a normalization model
You can now test your normalization model. You do this in the Normalization models view of the Normalization section, too. Proceed as follows (see the figure below - the numbers in the figure correspond with the numbered steps below):
- To open the Normalization models view in the nevisDetect web application,
- Select Normalizationfrom the top menu.
- Then select Normalization models in the navigation on the left.
- The Model test part of the Normalization models view defines the settings for testing your normalization models. This part contains the following elements:
- The models are tested for a specific user, which you define in the Login ID field (by entering the user's login ID). The Realm field allows setting the relevant authentication realm.
- All available normalizations models are listed next to the Login ID and Realm fields (see "b" in the figure). Enable the ones you want to include in the test. You can test several models at once.
- Clicking the Test model button triggers the testing of the selected normalization model(s).
- Click the Settings icon to set the test time frame.
- The graphic below the Test model button shows the test result. That is, the risk scores for the HTTP requests made by the respective user during the defined time frame.
- The graphic shows each risk score as a colored dot. The meaning of the colors is explained next to the graphic. In our example, dots with a bright green color represent the normalized risk score "test-corine". This is the name of the risk score calculated by our sample normalization model "Test-Corine". You define the name of a risk score and the color of the dots when defining the corresponding normalization model. Note that the graphic not only shows the normalized risk scores, but also the separate risk scores of the various plug-ins. Together, these plug-in risk scores make up the normalized risk score. These plug-in risk scores have another color, as you can see in the figure. If you want to exclude a specific risk score from the graphic, click on the corresponding color bar.
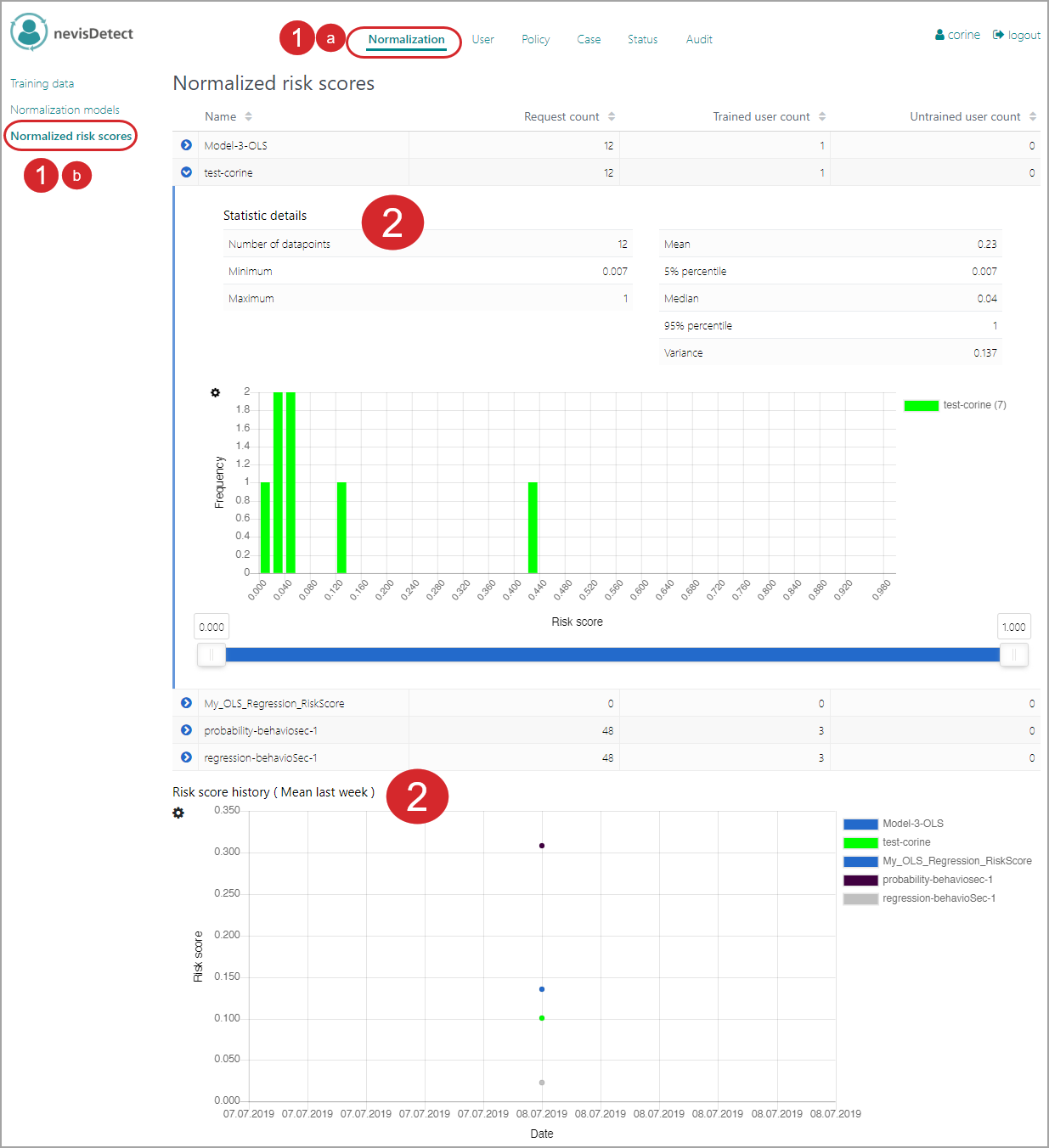
Use case: Viewing the statistic details of a model
The Normalized risk scores view of the Normalization section allows you to view the statistic details of a normalization model. Proceed as follows (see the figure below - the numbers in the figure correspond with the numbered steps below):
- To open the Normalized risk scores view in the nevisDetect web application,
- Select Normalizationfrom the top menu.
- Then select Normalized risk scores in the navigation on the left.
- The Normalized risk scores view contains the statistic details per model as well as a graphical representation of the risk score history. For a description of the view, see Normalization section, Normalized risk scores.