Kubernetes Infrastructure Inventory YAML file format
About the Kubernetes Inventory File
An inventory file is the place where the deployment environment is defined. It is
- The services section defines all Nevis components that are deployed. Each service will define one Nevis component.
- The groups section defines groups of services. For Kubernetes, groups are only used in advanced scenarios.
- The vars (variables) section contains variables which are defined for the whole inventory. Variables can also be defined at group or servicelevel.
- Thedeployment-repositorysection contains the configuration to connect to the Git deployment repository. Generated service configurations are transferred to Kubernetes via this repository.
- The kubernetes-clustersection contains the configuration to connect to the Kubernetes cluster for the deployment.
The services, deployment-repository and kubernetes-cluster sections are mandatory, whereas groups and vars are optional.
It is common practice to have more than one inventory file: namely one for each stage. For example: one inventory file describes the services used in your test stage and the second inventory file describes the services used in your production stage.
File format
The inventory file uses YAML syntax. To get familiar with the YAML syntax, use one of the many online tutorials. In YAML, indentation is a crucial part of the syntax and is done with spaces. If tab stops are used, this leads to syntax errors in YAML. The integrated editor converts a tab stop automatically into two spaces, but be careful when copy-pasting from external editors. The syntax is automatically validated while you are editing the inventory file. The green traffic light in the top right corner switches to red to indicate syntax violation. Hovering over the traffic light reveals details about the syntax violation.
Required attributes
A Kubernetes inventory file must contain the attributesschemaTypeand schemaVersion:
- The schemaType attribute defines the deployment type. Set the value to "Kubernetes" to indicate that it is a Kubernetes inventory. If schemaType is not set, the inventory will be considered classic.
- The schemaVersion attribute defines the version of the inventory, which ensures that future format changes can be handled.
Colors
Optionally, you can define a color for the inventory. This helps to distinguish between inventories at a glance. For example, it is possible to assign different colors for different stages.
The available values for color are:
- red
- yellow
- green
- purple
- brown
- blue
Sections
The main part of the inventory file consists of the following five sections: services, groups, vars, deployment-repository andkubernetes-cluster.
Example
schemaType: Kubernetes
schemaVersion: 1
color: Red
services:
<items>
groups:
<items>
vars:
<items>
deployment-repository:
<items>
kubernetes-cluster:
<items>
Services
The services section defines the Kubernetes services to be deployed. You can think about services as a list of Nevis components you want to deploy. Each service defines a logical set of Pods running a Nevis component. To get familiar with the Kubernetes concepts, use one of the many online tutorials.
Optionally, you can specify the version and the number of replicas of each service:
version: Defines the version of the component's Docker image to be deployed. By default it will take the latest version that has been tested with the pattern library you're using. You can configure the pattern library in your project settings.
replicas: Defines the number of Pods where the component will be replicated. By default it will create one replica.
requiredDBVersion: Defines the minimum version of the database schema required by the component. Warning: this is an advanced setting. We recommend that you do not change this setting. It means that the latest tested and supported version will be used.
database:
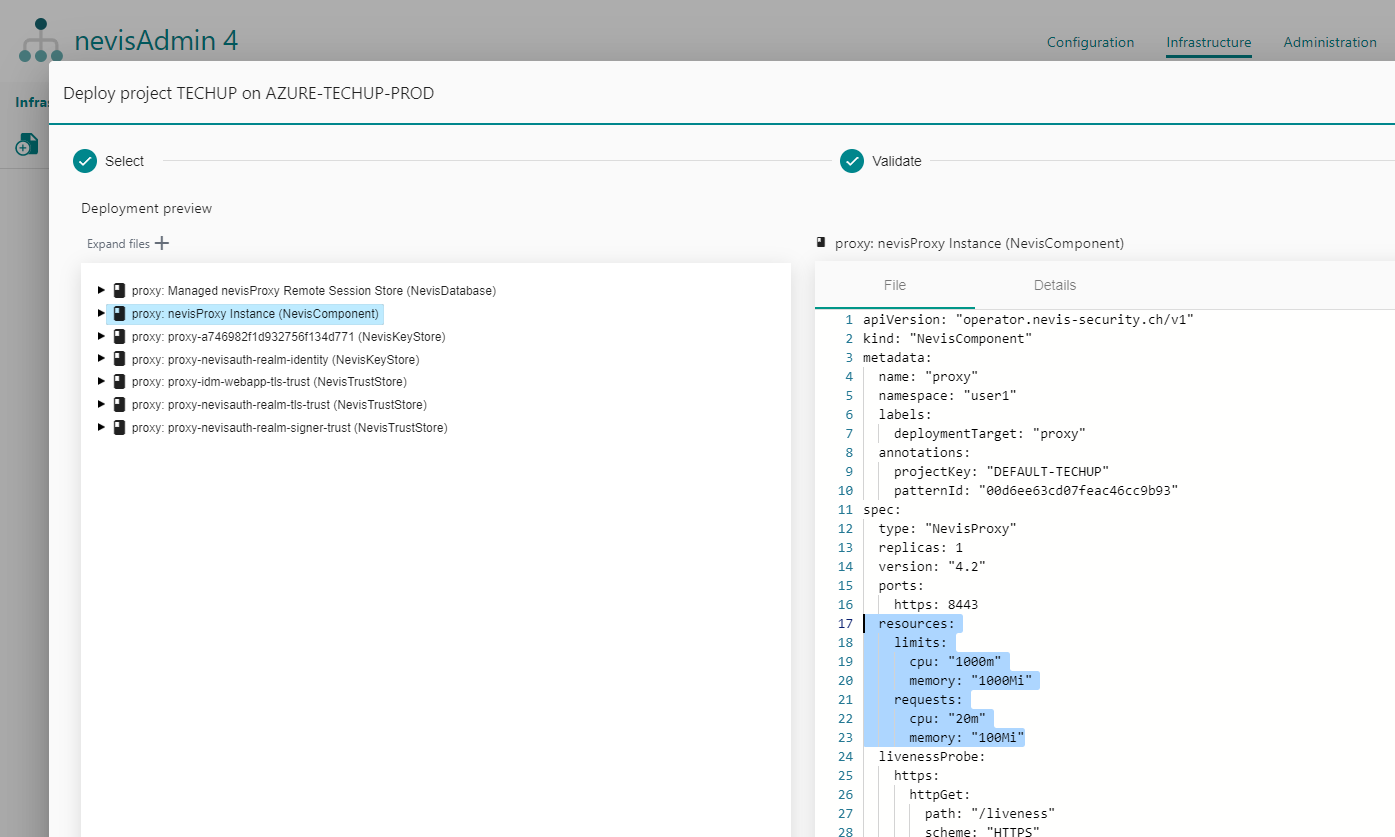
resources: Defines how much memory and CPU a component Pod can use. The defaults for your version of the nevisAdmin 4 pattern library can be seen in the generated NevisComponent resources in the deployment preview.
autoscaler:
affinity: Defines the affinity settings to be used for the component in Kubernetes format. A special placeholder {{postfix}} can be used to refer to the current side-by-side postfix.
custom-volumes**: Can be used to define custom volumes for the deployment. A list of volumeMount-volume pairs, see yaml example below.
pod-disruption-budget:
It's possible to set up the PDB in a way, that all pods must be available at all times, which means that the operations that effect nodes, such as node drain, cluster upgrade etc. will fail. Make sure to properly read through
<http://kubernetes.io/docs/concepts/workloads/pods/disruptions/#pod-disruption-budgets>and<http://kubernetes.io/docs/tasks/run-application/configure-pdb/>, paying a special attention to how the rounding is handled, before specifying a PDB.After the PDB is created, it can be further verified by checking that the allowed disruptions is at least one in the created resource.
services:
- ebanking-proxy:
kubernetes:
version: "3.14.0.1-32"
replicas: 2
requiredDBVersion: "0.1"
database:
version: "0.1"
resources:
limits:
cpu: 1000m
memory: 1000Mi
requests:
cpu: 20m
memory: 100Mi
autoscaler:
min-replicas: 2
max-replicas: 4
cpu-average-value-target: 600m
custom-volumes:
- volumeMount:
name: tz-istanbul
mountPath: /etc/localtime
volume:
name: tz-istanbul
hostPath:
path: /usr/share/zoneinfo/Europe/Istanbul
pod-disruption-budget:
max-unavailable: 50%
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: deploymentTarget
operator: In
values:
- ebanking-proxy{{postfix}}
topologyKey: kubernetes.io/hostname
- ebanking-auth
Default resources visible in the Deployment preview screen
In case you want all your services to have the same version and replicas, you can define these attributes as global inventory attributes:
services:
- ebanking-proxy
- ebanking-auth
kubernetes:
version: "3.14.0.1-32"
replicas: 2
Groups
The groups section organizes the previously defined services into one or more groups. Groups allow you to organize your inventory logically. As an example, you can structure the services in groups according to their functions within the Nevis Security Suite. Variables can also be defined at group level.
groups:
- proxies:
members:
- ebanking1-proxy
- ebanking2-proxy
vars:
public_DNS: www.muvonda.ch
- auths:
members:
- ebanking1-auth
- ebanking2-auth
- idms:
members:
- ebanking1-idm
- ebanking2-idm
vars:
database_primary: db-host1
database_secondary: db-host2
- ebanking1:
members:
- ebanking1-proxy
- ebanking1-auth
- ebanking1-idm
- ebanking2:
members:
- ebanking2-proxy
- ebanking2-auth
- ebanking2-idm
Vars (Variables)
The vars section defines variables that are valid for the entire inventory. This means that they are defined for every service in the services section. It is common practice to define variables at this level. In case some services or groups need different values for the same variable, they can be configured at the corresponding service or group level. Variable names consist only of letters, numbers, underscores and dashes. Keep in mind that variables defined on service level override variables defined on group level, which themselves override variables defined on inventory level. Try to keep the confusion at a minimum by defining the variables at the appropriate level, rather than using precedence.
Variables do not only support simple key/value pairs, but also more complicated structures, such as lists, dictionaries and even nested structures.
vars:
proxy_bind_address: https://www.muvonda.ch/
proxy_alias:
- https://www.nevis.ch/
- https://www.nevis-security.ch/
- https://www.nevis-security.de/
session:
ttl_max_sec: 43200
inactive_interval_sec: 1800
Deployment repository
In the deployment-repository section, the configuration of the version control repository used during the deployment is defined. During deployment, the generated Nevis configuration files will be pushed to this repository. Subsequently, the configuration will be fetched from within the Kubernetes cluster, to initialize the pods. The version control repository url and the branch must be defined.
deployment-repository:
url: ssh://[email protected]/siven/ebanking.git
branch: acceptancetest
Kubernetes cluster
In the kubernetes-cluster section, the configuration required to connect to the Kubernetes cluster is defined. You need to define the url of a running Kubernetes cluster, the namespace within the cluster and the token required to authenticate to the cluster. For security reasons, it is highly recommended adding the token as a secret.
kubernetes-cluster:
url: https://siven.kubernetes.cluster:443
namespace: siven-nva4
token: secret://E3103EA375S
Disable patterns
Instance patterns can not be disabled in Kubernetes deployments.
If you want to exclude some patterns from deployment, you can disable them in the inventory. For example, this allows you to apply a pattern in one stage while skipping it in another. The following predefined variables can be defined on services, groups or vars level:
- __disabled_patterns: This variable defines the list of patterns that must be disabled during the deployment. There are two ways to define a pattern: by its name or by referencing its ID. It is possible to combine both options on the same list.
- __disabled_pattern_types: Use this variable to disable all the patterns of a certain type. All the patterns belonging to the types defined in this list will be disabled during the deployment. Pattern types are defined by their class name.
vars:
__disabled_patterns:
- "SSO Realm"
- "pattern://d3f51b1fcbd3eaf433588645"
__disabled_pattern_types:
- "ch.nevis.admin.v4.plugin.nevisauth.patterns2.LdapLogin"